If you wish to get a head-start on the regular expressions, then there is surely one example. It is one which one has experienced hundreds of times. When one enters customer data online, there are many web forms which will ask one for an email address. To make sure that you do not type an incorrectly typed address, an immediate validation will surely make sense. There is one way which is to split the string in parts like before and after the @ character by analyzing the position of the dots as well as the number of characters right after the last dot. After a few ifs and loops, it is certainly almost done. Or one can simply use a regular expression:
ˆ[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)* @ [a-zA-Z0-9-]+\.([azA-Z]{2,3})$
Did one get that? Now for beginners with regular expressions, it is very hard to read. Regular expressions are a form of pattern with text. The whole expression is effectively encapsulated right as an object in a script or in programming language which would either be true or false. The result tells the caller whether the comparison is successful or not. Hence, the expression is better understood if it is the context of actual language. The article is dedicated to JavaScript, the usage in the language will look like:
var email = "[email protected]"; console.log(check(email)); function check(email) { if (email.match(/^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*@[a-zA-Z0-9-]+\\ .([a-zA-Z]{2,3})$/)) { return true; } else { return false; } }
The expression is made with the help of typical literals right as a boundary/ expression and the comparison is made by the match function which each string object provides. Make sure that the slashes are not put in quotes. It is literal that it creates an object.
How The Concept Works?
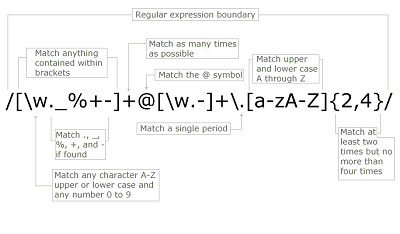
There might be a curiosity about how the expression works. If one start analyzing such expressions, then it is best to start with extraction of special characters. It certainly includes the particular expression: ˆ, $, +,*, ?, [], (). The other characters certainly do not possess a special meaning here. Regular characters are certainly a minority. Such patterns use placeholders with descriptive characters more than actual letters in the word.
Here is an overview of the special characters:
- ^ will let the recognition start right from the beginning. If one writes ˆx, it will match the letter “x” only if it appears at the very first character.
- $ will let one define where the pattern ends.
- * is the placeholder which will define no or any numbers of characters.
- + is a placeholder that mean one or any number of characters.
- ? is placeholder which will mean one or any number of characters.
- [a-z] will define one character out of group of letters or digits. One can use uppercase letters, lowercase letters or digits by placing them in brackets defining the range as shown in example.
- () groups characters or strings of characters. One can use set operators *, + and ? in the groups too.
- {} is the repetition marker which will define the character right before the braces. It can be repeated multiple times. The range can easily be defined by numbers; if the start and end are given separately, the numbers are written with a comma( {3,7})
- / (the backslash) masks meta characters with special characters so that they do no longer possess a special meaning.
- . represents exactly one character. If one actually need a dot, just write \.
Now one can easily split the expression quite well. The @ character will represents itself and first step will splits the expression:
1 ^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*
2 @
3 [a-zA-Z0-9-]+\.([a-zA-Z]{2,3})$
The part right before the @ character, there must have at least one character. This is forced right by the first character definition [[_a-zA-Z0-9-] with acceptable characters together with + sign. Then, the expressions will followed by actual dot\., which by itself is followed by one or more characters. The whole “dot plus more characters” group is optional with the remaining part of two or three characters long.
Also Read,

Ayan Sarkar
Ayan Sarkar is one of the youngest entrepreneurs of India. Possessing the talent of creative designing and development, Ayan is also interested in innovative technologies and believes in compiling them together to build unique digital solutions. He has worked as a consultant for various companies and has proved to be a value-added asset for each of them. With years of experience in web development, product managing and building domains for customers, he currently holds the position of the CTO in Webskitters Technology Solutions Pvt. Ltd.
Search
I Want to Learn...



Category
Explore OurAll CoursesTransform Your Dreams
into Reality
Subscribe to Our Newsletter
"*" indicates required fields